If you go to http://NAMENODE_MACHINE_NAME:50070/ in your browser it should take you to a page with a Browse the filesystem link.
In the $HIVE_HOME/conf directory there is the hive-default.xml and/or hive-site.xml which has the hive.metastore.warehouse.dir property. That is the value where you will be navigated, after clicking the Browse the filesystem link.
Usually, for systems, it is /user/hive/warehouse. Once you go to that location, you will see the names of the existing tables. Clicking on a table name (which is just a folder) you will see the partitions of the table. When you click on the folder at this level, you will see files (more partitioning will create more levels). These files are where the data is actually stored on the HDFS.
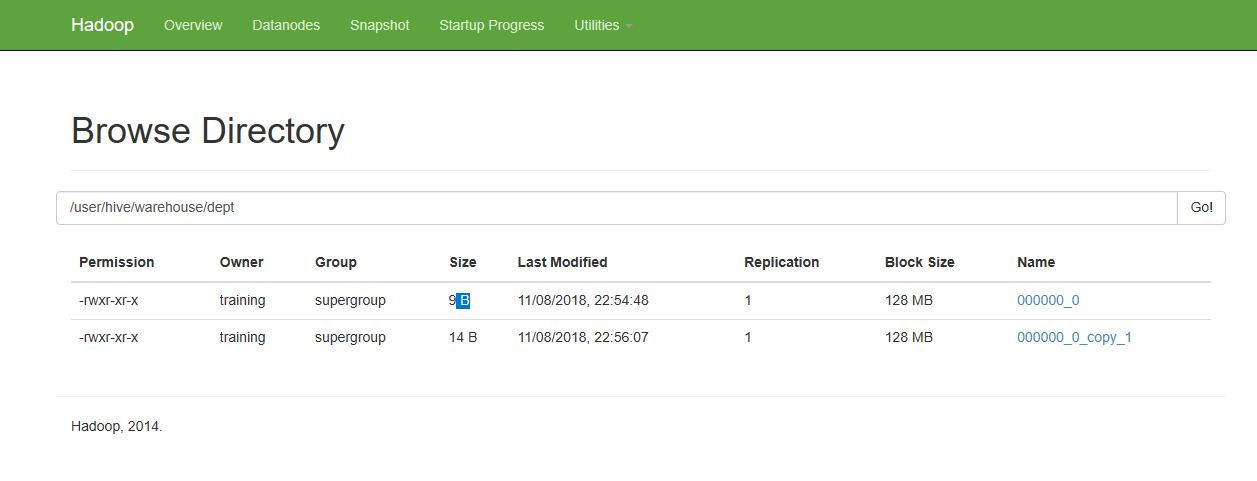
Hive stores data inside /hive/warehouse folder on HDFS if not specified any other folder using LOCATION tag while creation. It is stored in various formats (text,rc,csv,orc etc).
Accessing Hive files (data inside tables) through PIG:
This can be done even without using HCatalog.
1. Create Hive table using
Create table tableA (
col1 string,
col2 string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '^'
LOCATION '/data/tableA';
where, /data/tableA location is HDFS Location and has CSVs (data) separated by ^.
If you want more information regarding the Hive, refer to the following video tutorial: