When a reduceByKey function is applied on a Spark RDD, it merges the values for each key by using an associative reduce function.
Associative functions helps us in doing parallel computation. Here we break an original collection into pieces and then apply the associative function, that is further accumulated as a total.
Also, Associativity allows us to use that same function in sequence and in parallel.
This property is used by reduceByKey transformation in order to compute a result out of an RDD.
Consider the following example:
// Here, collection of the form ("key",1),("key,2),...,("key",15) splits among 3 partitions
val rdd =sparkContext.parallelize(( (1 to 15).map(x=>("key",x))), 3)
rdd.reduceByKey(_ + _)
rdd.collect()
> Array[(String, Int)] = Array((key,))
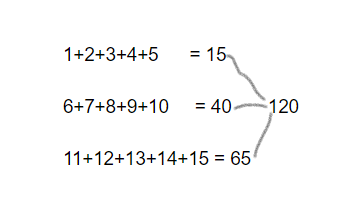
In spark, data is distributed into partitions. For the next illustration, (3) partitions are to the left, enclosed in thin lines. First, we apply the function locally to each partition, sequentially in the partition, but we run all 3 partitions in parallel. After that, the result of each local computation is aggregated by applying the same function again and eventually the result is produced.