Go to your Hadoop Server 'localhost:9000'. There click on the Utility column at the top and go to Logs. Then , userlogs, there checkout for your completed job-> click on the map or reduce task-> select the task number-> then task log files will appear, finally select your stdout log.
Another way through the terminal:
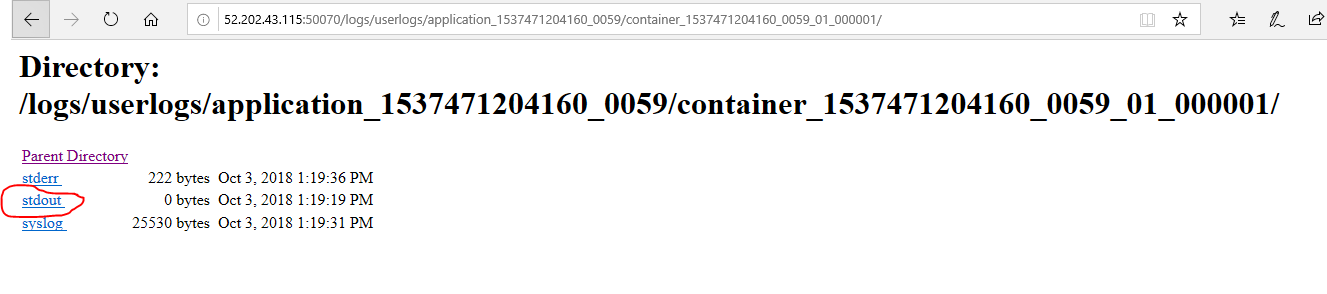
Go into your Hadoop directory, then go to "logs/userlogs/ job_id directory”.
Now, check for mapper or reducer directories that may be assigned with _m_ and _r_ respectively, out of both whichever you're looking for, go to that directory.
To determine the types of log files that are available for this container(stdout, stderr, syslog) and the path to each available log file, run the command given below, according to your system
>hadoop fs -ls <link location>
For example -
>hadoop fs -ls
../var/mapr/local/qa-node178.qa.lab/logs/yarn/userlogs/application_1434605941718_0001/container_e02_1434605941718_0001_01_000003
The path of the log files(stdout, stderr, syslog) generated as an output.
log.index stderr stdout syslog
Now, to view the System.out.println() for map or reduce phases, in desired log file(stdout) run the following command:
>hadoop fs- cat ../../../../var/mapr/local/qa-node178.qa.lab/logs/yarn/userlogs/application_1434605941718_0001/container_e02_1434605941718_0001_01_000003/stdout
If you want more information regarding the same, refer the following video: