I would suggest you to try to increase memory to spark.python.worker.memory default (512m) because of heavy Python code and this property value does not count in spark.executor.memory.
The amount of memory to use per python worker process during aggregation, in the same format as JVM memory strings (e.g. 512m, 2g). If in any case the memory used during aggregation goes above this amount, it is going to spill the data into disks. Check this link.
ExecutorMemoryOverhead calculation in Spark:
MEMORY_OVERHEAD_FRACTION = 0.10
MEMORY_OVERHEAD_MINIMUM = 384
val executorMemoryOverhead =
max(MEMORY_OVERHEAD_FRACTION * ${spark.executor.memory}, MEMORY_OVERHEAD_MINIMUM))
The property is spark.{yarn|mesos}.executor.memoryOverhead for YARN and Mesos.
YARN automatically kills the processes which takes more memory than they requested which is the sum of executorMemoryOverhead and executorMemory.
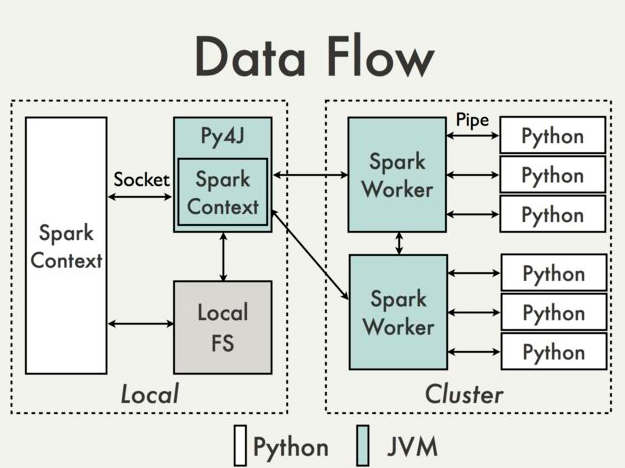
In the image given below python processes in worker uses spark.python.worker.memory, then spark.yarn.executor.memoryOverhead + spark.executor.memory is specific JVM.