Support Vector Machines: SVM is a commonly used machine learning algorithm. It works on the principle to find a hyperplane that divides the two classes with the largest margin.most of the data points which fall within this margin.
It performs classification in the following ways:
Hard Margin Linear SVM
If data is linearly separable, then you can use a hard margin SVM classifier, the support vectors in this technique are the points which lie along the supporting hyperplanes.
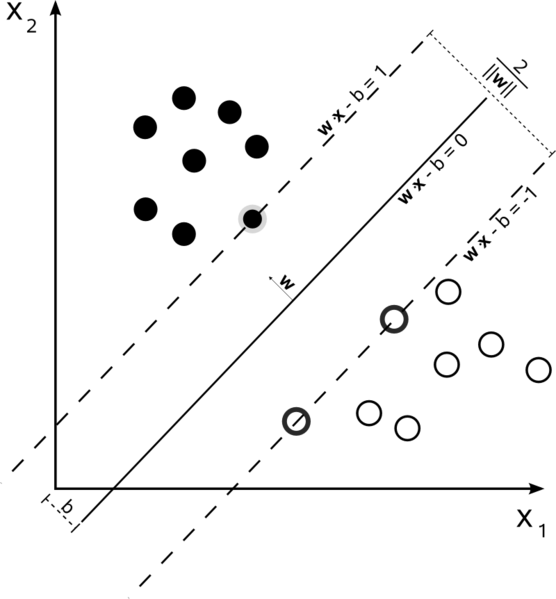
Almost every support vectors lie exactly on the margin. Support vectors are independent of the number of dimensions or size of the data set, the number of support vectors can be at least two.
Soft-Margin Linear SVM
This technique is used when data is non- linearly separable. It is not required that our data points lie outside the margin. There is a slack parameter C used to control this. This gives us a larger margin and greater error on the training dataset, but improves generalization and/or allows us to find a linear separation of data that is not linearly separable.
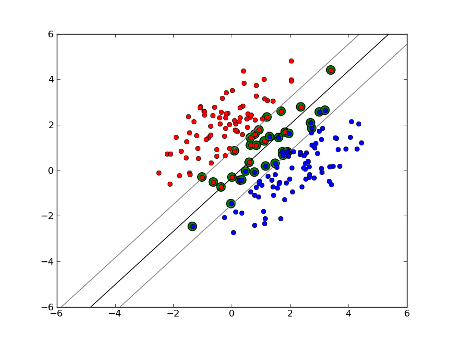
Non-Linear SVM
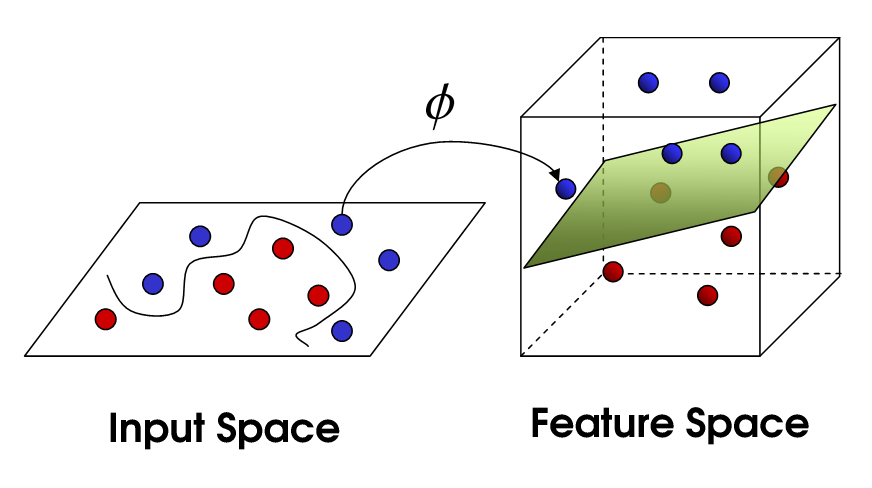
We use different kernel functions in SVM. They have their own set of parameters. When we translate this back to the original feature space, the result is non-linear:
Hope this answer helps.