Spark Standalone mode runs on a master-slave architecture..
Answering your 3 questions:
1. Does 2 worker instance mean one worker node with 2 worker processes?
In general, the term used for worker instance is called slave as it's a process to execute spark tasks/jobs. Suggested mapping for node(a physical or virtual machine) and worker is:
1 Node = 1 Worker process
2. Does every worker instance hold an executor for specific application (which manages storage, task) or one worker node holds one executor?
Yes,if the worker node has sufficient CPU, Memory and Storage, it may hold multiple executors (processes) .
Check this worker node image:

In a worker node the number of executors at a given point of time entirely depends upon the work load on the cluster and capability of the node to run the no of executors.
3. Is there a flow chart explain how spark runtime?
Keeping in mind the execution from Spark prospective over any resource manager for a program, below is the flow chart where joining of two rdds is done and some reduce operations are performed and then finally filter() is called:
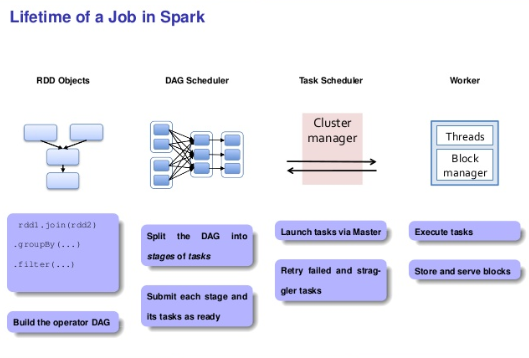
If you want to know more about Spark, then do check out this awesome video tutorial: