There are many unsupervised learning algorithms. K-means clustering is most commonly used for grouping of data. In k-means grouping is done based on the similarity of features. It is the simplest unsupervised learning algorithm that solves the clustering problem.
In the bike-sharing dataset, grouping can be done based on ‘proximity of area’ or ‘age’ or ‘gender’ of the bike users. You will find more about this once you implement the k-means algorithm.
You can find more about this algorithm here.
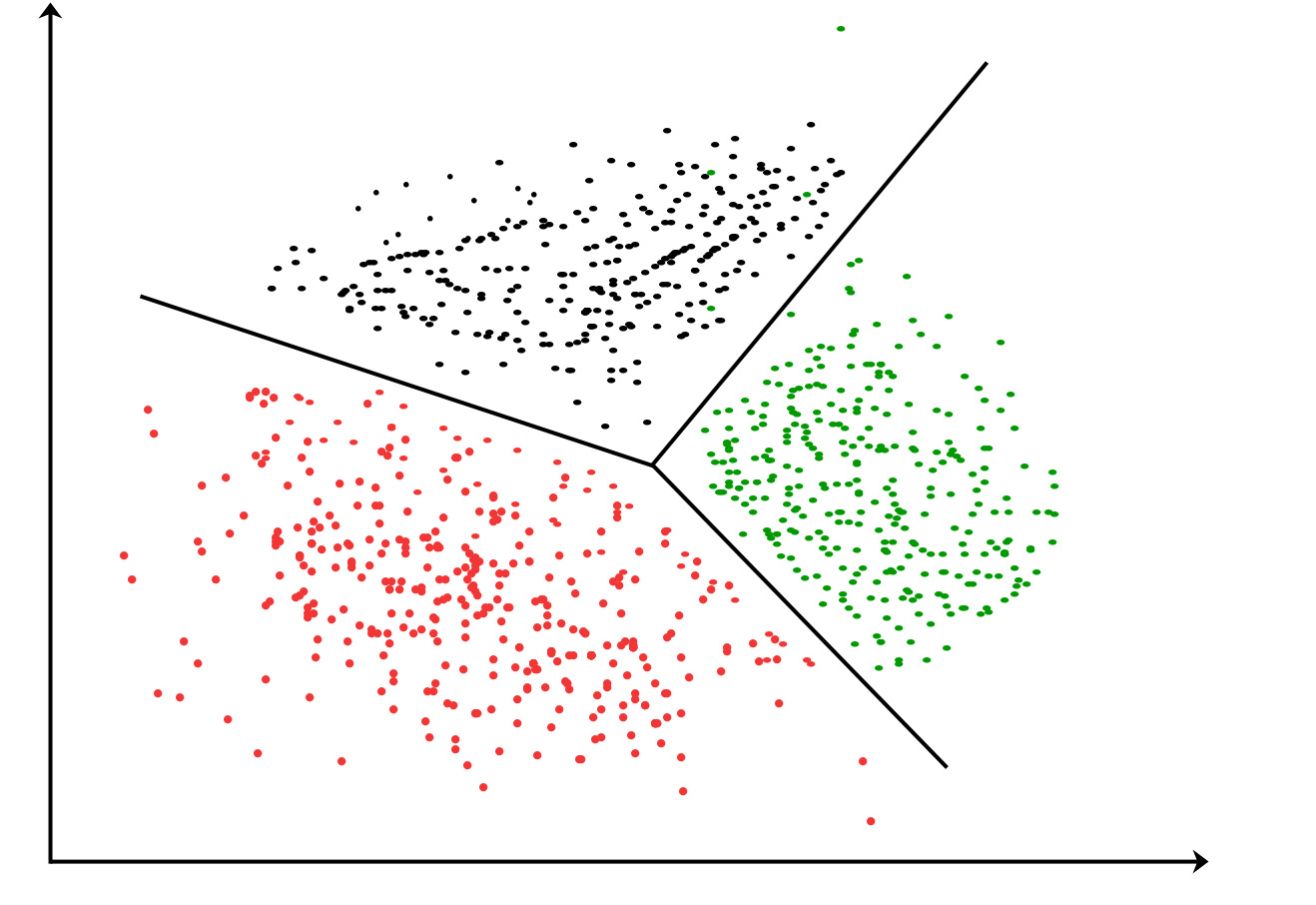
It works by dividing a large set of points (vectors) into groups having approximately the same number of points closest to them. Each group is represented by its centroid point, as in k-means and some other clustering algorithms.
Some other fields related to clustering are
Marketing
Biology
Libraries
Insurance
City Planning
Earthquake studies
And many more…
There are many other applications of clustering, depends on the dataset, you want to work on.
If you want to know about Supervised and Unsupervised Machine Learning then you can watch this video tutorial: