Recently I've been reading a lot about Q-learning with Neural Networks and thought about to update an existing old optimization system in a power plant boiler composed of a simple feed-forward neural network approximating an output from many sensory inputs. The output then is linked to a linear model-based controller that somehow output again an optimal action so the whole model can converge to the desired goal.
Identifying linear models is a consuming task. I thought about refurbishing the whole thing to model-free Q-learning with a Neural Network approximation of the Q-function. I drew a diagram to ask you if I'm on the right track or not.
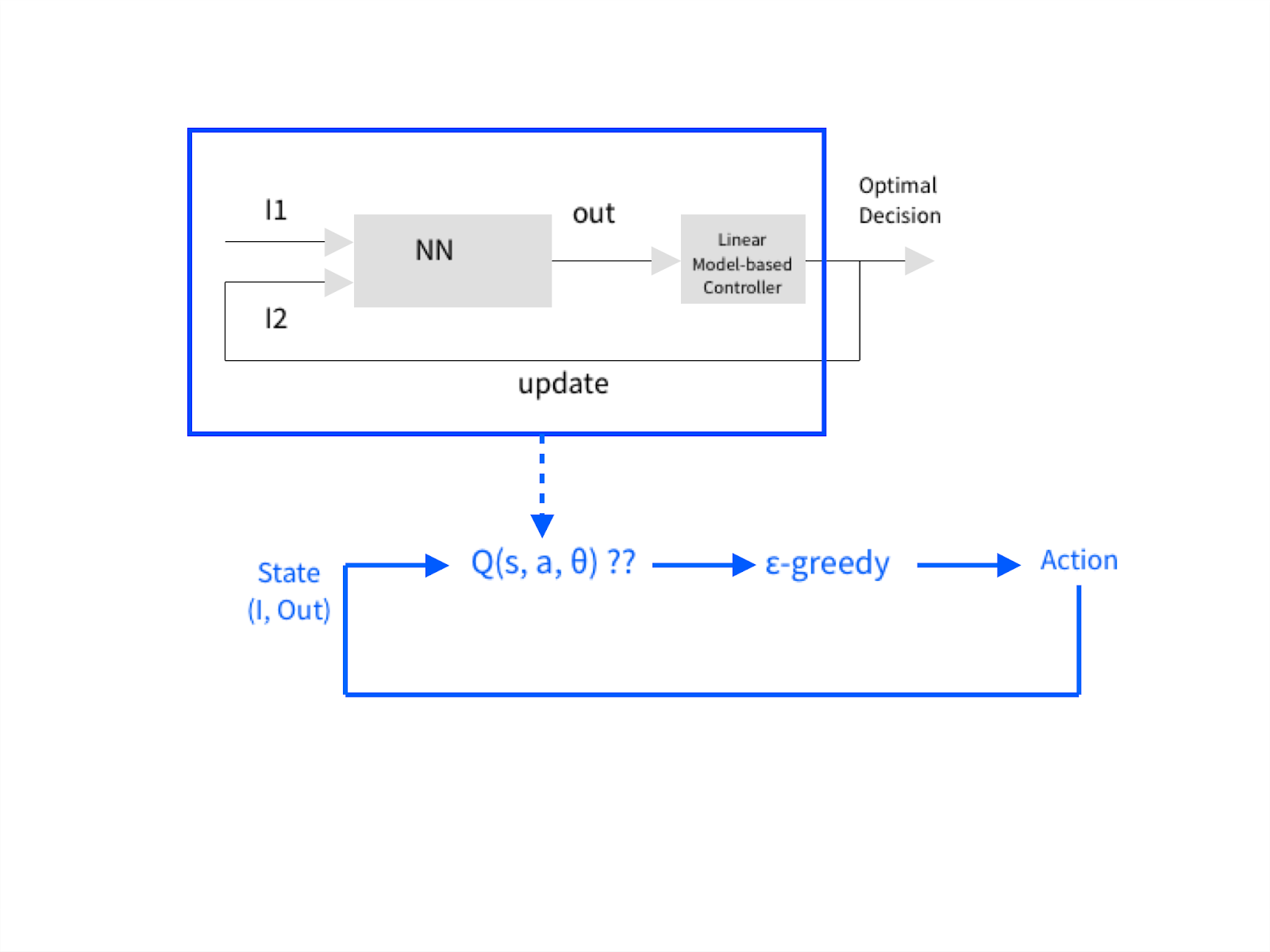
My question: if you think I understood well the concept, should my training set be composed of State Features vectors from one side and Q_target - Q_current (here I'm assuming there's an increasing reward) in order to force the whole model towards the target or am I missing something?
Note: The diagram shows a comparison between the old system in the upper part and my proposed change on the lower part.
EDIT: Does a State Neural Network guarantee Experience Replay?