I am currently trying to understand the architecture behind the word2vec neural net learning algorithm, for representing words as vectors based on their context.
After reading Tomas Mikolov paper I came across what he defines as a projection layer. Even though this term is widely used when referred to word2vec, I couldn't find a precise definition of what it actually is in the neural net context.
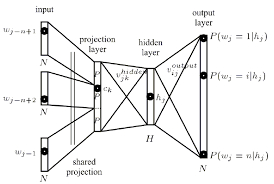
My question is, in the neural net context, what is a projection layer? Is it the name given to a hidden layer whose links to previous nodes share the same weights? Do its units actually have an activation function of some kind?
Another resource that also refers more broadly to the problem can be found in this tutorial, which also refers to a projection layer around page 67.