If all you want to do is map a word to a vector, you can simply use the [] operator, e.g. model["hello"] will give you the vector corresponding to hello.
If you need to recover a word from a vector you could loop through your list of vectors and check for a match, as you propose. However, this is inefficient and not pythonic. A convenient solution is to use the similar_by_vector method of the word2vec model, like this:
import gensim
documents = [['human', 'interface', 'computer'],
['survey', 'user', 'computer', 'system', 'response', 'time'],
['eps', 'user', 'interface', 'system'],
['system', 'human', 'system', 'eps'],
['user', 'response', 'time'],
['trees'],
['graph', 'trees'],
['graph', 'minors', 'trees'],
['graph', 'minors', 'survey']]
model = gensim.models.Word2Vec(documents, min_count=1)
print model.similar_by_vector(model["survey"], topn=1)
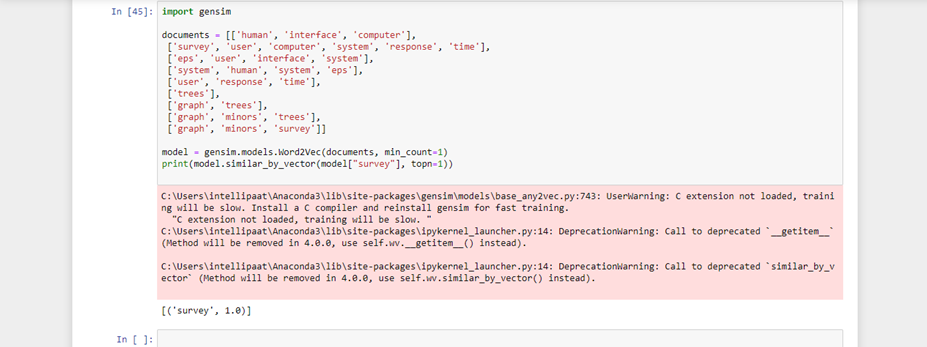
where the number represents the similarity.
However, this method is still inefficient, as it still has to scan all of the word vectors to search for the most similar one. The best solution to your problem is to find a way to keep track of your vectors during the clustering process so you don't have to rely on expensive reverse mappings.
Machine Learning is one of the topics where this is associated. So, studying a Machine Learning Course will be giving you a broader outreach on this.