Training a kNN classifier simply consists of determining k and preprocessing documents. If we preselect some value for k and do not preprocess it, then kNN requires no training at all. In practice, we have to perform preprocessing steps like tokenization. It makes more sense to preprocess the training documents once as part of the training phase rather than repeatedly every time we classify a new test document.
Test time is 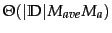 for kNN. It has a linear size of the training set as we need to compute the distance of each training document from the test document. Test time is independent of the number of classes J. kNN, therefore, has a potential advantage for problems with large J.
for kNN. It has a linear size of the training set as we need to compute the distance of each training document from the test document. Test time is independent of the number of classes J. kNN, therefore, has a potential advantage for problems with large J.
In short:
large value of K = simple model = underfit = low variance & high bias
Small vlaue of K = complex model =overfit = high variance& low bias
If you wish to know more about K-means Clustering then visit this K-means Clustering Algorithm Tutorial.