Kappa architecture is a software architecture that mainly focuses on stream processing data. Here we have a canonical datastore that is an append-only immutable log store present as a part of Kappa architecture. From this log, the streaming of data is done through the computational system and fed into the serving layer for query handling purposes.
Some of the log databases are -
Apache Kafka
Apache Pulsar
Pravega
Kappa architecture mainly consists of two layers -
The work of stream processing layer is to run the stream processing jobs whereas the serving layer is used to store the results and also give responses to queries made on these results. In stream processing, we have to deal with streaming data and take real-time decisions.
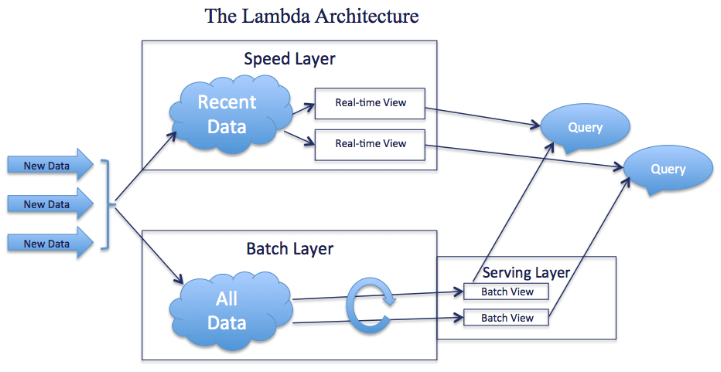
The Kappa architecture works with just stream processing as it is a simplified version of Lambda architecture. In Lambda architecture we have both stream processing layer and batch processing layer, where stream layer is used to compute the real-time data and batch layer stores the raw data as it arrives and computes it after some interval of time i.e it is not continuous like stream processing.
Thus, The Kappa architecture is a sum up of speed layer and serving layer while other stream processing tools is a sum up of speed layer and batch layer(as it contains lambda architecture).
If you want more information regarding the same, refer to the following video: