I have an artificial neural network that plays Tic-Tac-Toe - but it is not complete yet.
What I have yet:
the reward array "R[t]" with integer values for every timestep or move "t" (1=player A wins, 0=draw, -1=player B wins)
The input values are correctly propagated through the network.
the formula for adjusting the weights:
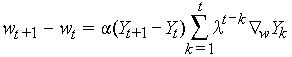
What is missing:
But I don't understand this algorithm.
My approach so far ...
The trace decay parameter λ should be "0.1" as distal states should not get that much of the reward.
The learning rate is "0.5" in both layers (input and hidden).
It's a case of delayed reward: The reward remains "0" until the game ends. Then the reward becomes "1" for the first player's win, "-1" for the second player's win or "0" in case of a draw.
My questions:
How and when do you calculate the net's error (TD error)?
How can you implement the "backpropagation" of the error?
How are the weights adjusted using TD(λ)?
Thank you so much in advance :)