I have a maze-like the following:

The goal is for P to find +, with sub-goals of
I'm trying to understand why my A* heuristic is performing so much worse than an implementation I have for Greedy Best First. Here are the two bits of code for each:
#Greedy Best First -- Manhattan Distance
self.heuristic = abs(goalNodeXY[1] - self.xy[1]) + abs(goalNodeXY[0] - self.xy[0])
#A* -- Manhattan Distance + Path Cost from 'startNode' to 'currentNode'
return abs(goalNodeXY[1] - self.xy[1]) + abs(goalNodeXY[0] - self.xy[0]) + self.costFromStart
In both algorithms, I'm using a heapq, prioritizing based on the heuristic value. The primary search loop is the same for both:
theFrontier = []
heapq.heappush(theFrontier, (stateNode.heuristic, stateNode)) #populate frontier with 'start copy' as only available Node
#while !goal and frontier !empty
while not GOAL_STATE and theFrontier:
stateNode = heapq.heappop(theFrontier)[1] #heappop returns tuple of (weighted-idx, data)
CHECKED_NODES.append(stateNode.xy)
while stateNode.moves and not GOAL_STATE:
EXPANDED_NODES += 1
moveDirection = heapq.heappop(stateNode.moves)[1]
nextNode = Node()
nextNode.setParent(stateNode)
#this makes a call to setHeuristic
nextNode.setLocation((stateNode.xy[0] + moveDirection[0], stateNode.xy[1] + moveDirection[1]))
if nextNode.xy not in CHECKED_NODES and not isInFrontier(nextNode):
if nextNode.checkGoal(): break
nextNode.populateMoves()
heapq.heappush(theFrontier, (nextNode.heuristic,nextNode))
So now we come to the issue. While A* finds the optimal path, it's pretty expensive at doing so. To find the optimal path of cost:68, it expands (navigates and searches through) 452 nodes to do so.
To find the optimal path of cost:68, it expands (navigates and searches through) 452 nodes to do so.

While the Greedy Best implementation I have finds a sub-optimal path (cost: 74) in only 160 expansions.
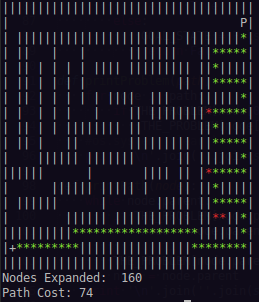
I'm really trying to understand where I'm going wrong here. I realize that Greedy Best First algorithms can behave like this naturally, but the gap in node expansions is just so large I feel like something has to be wrong here... any help would be appreciated. I'm happy to add details if what I've posted above is unclear in some way.