Constructing a Discrete Probability Distributions with Example
Probability Functions and Distribution Functions
(a) Probability Functions
Say the possible values of a discrete random variable, X, are x0, x1, x2, … xk, and the corresponding probabilities are p(x0), p(x1), p(x2) … p(xk). Then for any choice of i,
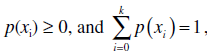
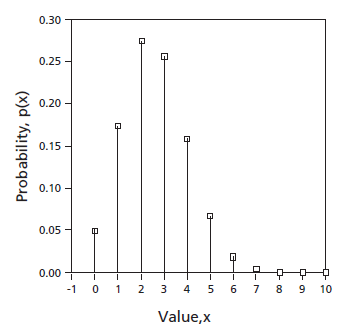
where k is the maximum possible value of i. Then p(xi) is a probability function, also called a probability mass function. An alternative notation is that the probability function of X is written Pr [X = xi]. In many cases p(xi) (or Pr[X = xi]) and xi are related by an algebraic function, but in other cases the relation is shown in the form of a table. The relation can be represented by isolated spikes on a bar graph.
By convention the random variable is represented by a capital letter (for example, X), and particular values are represented by lower-case letters (for example, x, xi, x0).
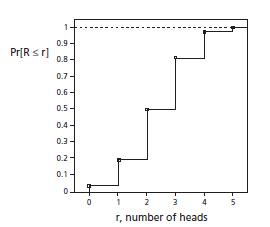
(b) Cumulative Distribution Functions in Probability
Cumulative probabilities, Pr [X ≤x], where X still represents the random variable and x now represents an upper limit, are found by adding individual probabilities.
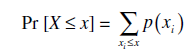
where p(xi) is an individual probability function. For example, if xi can be only zero or a positive integer,
Pr [X ≤ 3] = p(0) + p(1) + p(2) + p(3)
The functional relationship between the cumulative probability and the upper limit, x, is called the cumulative distribution function, or the probability distribution function.
Expectation and Variance in Probability
(a) Expectation of a Random Variable
The mathematical expectation or expected value of a random variable is an arithmetic mean that we can expect to closely approximate the mean result from a very long series of trials, if a particular probability function is followed. The expected value is the mean of all possible results for an infinite number of trials. We must know the complete probability function in order to calculate the expectation.
The expectation of a random variable X is denoted by E(X) or μx or μ. The last two symbols indicate that the expectation or expected value is the mean value of the distribution of the random variable.
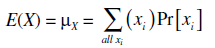
(b) Variance of a Discrete Random Variable
The variance was defined for the frequency distribution of a population. The mean value of (xi – μ)2. Since the quantity corresponding to the mean for a probability distribution is the expectation, the variance of a discrete random variable must be –
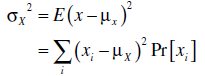
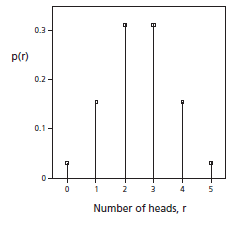
Binomial Distribution in Probability
This important distribution applies in some cases to repeated trials where there are only two possible outcomes: heads or tails, success or failure, defective item or good item, or many other possible pairs. The probability of each outcome can be calculated using the multiplication rule, perhaps with a tree diagram, but it is usually much faster and more convenient to use a general formula.
The requirements for using the binomial distribution are as follows:
- The outcome is determined completely by chance.
- There are only two possible outcomes.
- All trials have the same probability for a particular outcome in a single trial. That is, the probability in a subsequent trial is independent of the outcome of a previous trial. Let this constant probability for a single trial be p.
- The number of trials, n, must be fixed, regardless of the outcome of each trial.
Poisson Distribution in Probability
This is a discrete distribution that is used in two situations. It is used, when certain conditions are met, as a probability distribution in its own right, and it is also used as a convenient approximation to the binomial distribution in some circumstances.
The Poisson distribution in Probability applies in its own right where the possible number of discrete occurrences is much larger than the average number of occurrences in a given interval of time or space. The number of possible occurrences is often not known exactly.
The outcomes must occur randomly, that is, completely by chance, and the probability of occurrence must not be affected by whether or not the outcomes occurred previously, so the occurrences are independent.

Calculation of Poisson Probabilities
The probability of exactly r occurrences in a fixed interval of time or space under particular conditions is given by
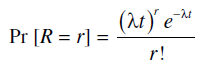
where t (in units of time, length, area or volume) is an interval of time or space in which the events occur, and λ is the mean rate of occurrence per unit time or space (so that the product λt is dimensionless). As usual, e is the base ofnatural logarithms, approximately 2.71828.
Relation between Probability Distributions and Frequency Distributions
Probability distributions show predictable variations with the values of the variable. Frequency distributions show additional random variations, that is, variations which depend on chance.
Random numbers can be used to simulate frequency distributions corresponding to various discrete random variables. That is, random numbers can be combined with the parameters of a probability distribution to produce a simulated frequency distribution.
(a) Comparison of a Probability Distribution with Corresponding Simulated Frequency Distributions
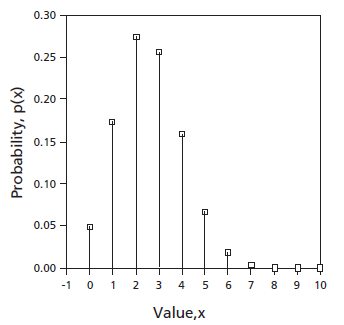
Corresponding to this is Figure: Simulated Frequency Distributions for Eight Repetitions, which is for the same values of n and p but shows two simulated relative frequency distributions. These are for samples of size eight—that is, samples containing eight items each. As we have seen before, relative frequencies are often used as estimates of probabilities. However, with this small sample size the relative frequencies do not agree at all well with the corresponding probabilities, and they do not agree with one another.
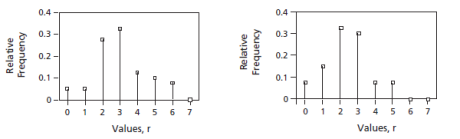
If the sample size is increased, agreement becomes better.
(b)Fitting a Binomial Distribution in Probability
The binomial distribution has two parameters, n and p. In any practical case we will already know n, the number of trials. How can we estimate p, the probability of “success” in a single trial? An intuitive answer is that we can estimate p by the fraction of all the trials which were “successes,” that is, the proportion or relative frequency of “success.” It is possible to show mathematically that this intuitive answer is correct, an unbiased estimate of the parameter p.
(c)Fitting a Poisson Distribution in Probability
The Poisson distribution in Probability has only one parameter, μ or λt. The sample mean, x, is an unbiased estimate of the population mean, μ. Therefore, the first step in fitting a Poisson distribution to a set of data is to calculate the mean of the data.
Then the relation for the Poisson distribution is used to calculate the probabilities of various numbers of occurrences if that distribution holds. These probabilities can be compared to the relative frequencies found by dividing the actual frequencies by the total frequency.
Enroll in our Data Analyst Course and become a certified Data Analyst!